This chapter focuses on the synthesis of concepts.TrueBy the end of this chapter, you will be able to:
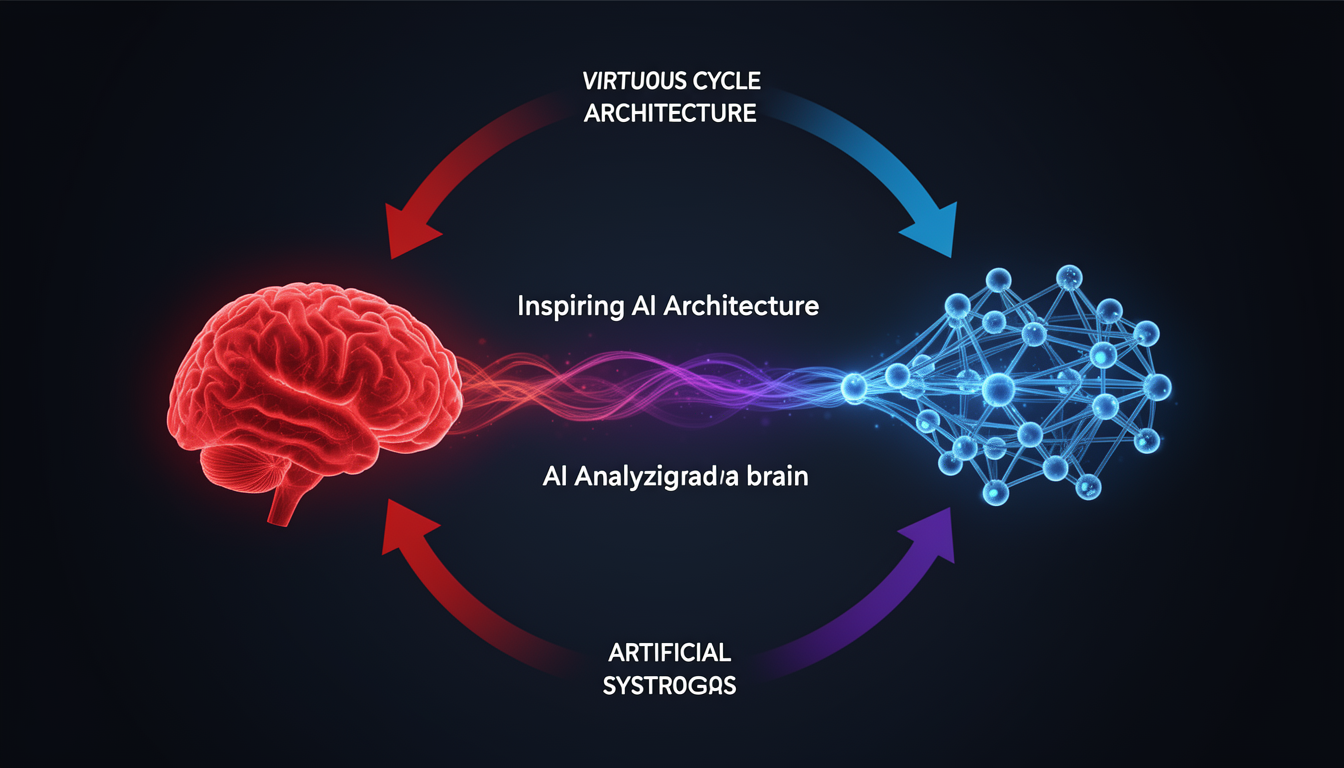
Throughout this handbook, we have explored the brain and artificial intelligence, often drawing parallels between them. This chapter formalizes that connection, moving beyond simple analogies to explore the powerful, bidirectional relationship between these two fields. Building on the historical dialogue introduced in Chapter 1, we now examine the heart of NeuroAI: a virtuous cycle where each field alternately inspires and enables the other.
The cycle proceeds in two main directions: 1. Brain as Inspiration for AI: Neuroscientific discoveries about the brain’s structure and function provide blueprints and principles for designing new artificial learning systems. 2. AI as a Tool for Neuroscience: Artificial intelligence, particularly deep learning, provides an unprecedented toolkit for modeling neural data, testing theories of brain function, and accelerating scientific discovery.
This chapter will explore this cycle through concrete case studies, distill key lessons from the brain for future AI, and look ahead to the next frontiers of this exciting synthesis.
 Figure 17.1: The virtuous cycle of NeuroAI. Discoveries in neuroscience inspire new AI architectures. These AI models then become powerful tools for analyzing neural data and testing theories, leading to new neuroscientific discoveries.
Figure 17.1: The virtuous cycle of NeuroAI. Discoveries in neuroscience inspire new AI architectures. These AI models then become powerful tools for analyzing neural data and testing theories, leading to new neuroscientific discoveries.
Perhaps the most famous and successful example of the NeuroAI virtuous cycle is the story of the visual system and Convolutional Neural Networks (CNNs).
Step 1: Neuroscience Inspires AI
In the 1950s and 60s, neuroscientists David Hubel and Torsten Wiesel conducted groundbreaking experiments on the visual cortex of cats. They discovered that neurons in the primary visual cortex (V1) act as specialized feature detectors, responding selectively to simple patterns like edges at specific orientations. They also found that these simple features were combined in higher visual areas to detect more complex shapes. This revealed the brain’s hierarchical and spatially organized approach to vision.
Inspired directly by this discovery, computer scientist Kunihiko Fukushima developed the “Neocognitron” in 1980, a precursor to modern CNNs. This work was later refined by Yann LeCun and others in the 1990s, leading to the creation of the first modern CNNs, which explicitly incorporated two of the brain’s key principles: - Local Receptive Fields: Each “neuron” (filter) only looks at a small patch of the input image. - Hierarchical Processing: The output of one layer of feature detectors becomes the input for the next, allowing the network to build up representations of increasing complexity (edges -> textures -> object parts -> objects).
Step 2: AI Enables Neuroscience
For decades, CNNs were a promising but niche technology. However, with the advent of large datasets (like ImageNet) and powerful GPUs, deep CNNs like AlexNet (2012) achieved superhuman performance on image classification. This success was so profound that neuroscientists began to wonder: are these models just good at the task, or are they actually processing visual information like the brain does?
Researchers like DiCarlo’s lab at MIT used CNNs as in silico models of the primate ventral visual stream. They found remarkable parallels: - Representational Similarity: The pattern of activations in a CNN’s layers in response to a set of images closely matched the pattern of neural firings in corresponding areas of the visual cortex. - Predictive Power: The activations of a trained CNN could predict the firing rate of a real neuron in a monkey’s brain with stunning accuracy. In fact, deep CNNs became the best predictive models of the ventral visual stream, outperforming all previous neuroscience models.
This closed the loop. A neuroscientific discovery inspired an AI architecture, which, once scaled, became the most powerful tool available for testing and advancing theories about the very brain region that inspired it.
Technical Deep-Dive: The correspondence between CNNs and the visual system goes beyond high-level principles. Specific properties match remarkably well: - Receptive Field Sizes: As you ascend the CNN hierarchy, receptive fields grow larger, matching the progression from V1 (small, local) to V4 to IT (large, global) - Feature Selectivity: Early CNN layers detect oriented edges and simple patterns (V1); middle layers detect textures and parts (V2/V4); late layers detect whole objects and faces (IT) - Invariance: Both systems build increasing invariance to transformations: early layers are sensitive to exact position, while late layers respond to objects regardless of position, size, or orientation
Quantitative Benchmarks: DiCarlo’s lab showed that the best CNN models explain ~60% of variance in IT neural responses, better than any hand-crafted neuroscience model. This doesn’t mean CNNs are the visual cortex, but they’re the best computational models we have.
Limitations: Critical differences remain: - CNNs require millions of labeled examples; humans learn object categories from handfuls - CNNs are fooled by adversarial examples imperceptible to humans - CNNs lack recurrent dynamics and attentional modulation that characterize biological vision These gaps indicate where neuroscience can still inform AI development.

A second powerful example of the virtuous cycle comes from the study of learning and decision-making.
Step 1: AI Formalizes a Learning Theory
Drawing inspiration from psychological studies of animal behavior (like Pavlov’s dogs), AI researchers in the 1980s, notably Rich Sutton and Andrew Barto, developed the mathematical framework of Reinforcement Learning (RL). A key breakthrough was the Temporal Difference (TD) learning algorithm. TD learning proposed a mechanism for learning from delayed rewards by computing a “prediction error”—the difference between an expected future reward and the actual reward received.
Step 2: Neuroscience Discovers the Biological Substrate
In the 1990s, neuroscientists Wolfram Schultz and colleagues were recording from the brains of monkeys as they learned to associate a stimulus (like a light) with a reward (a drop of juice). They discovered that dopamine neurons in the midbrain behaved exactly as predicted by the TD learning algorithm. - Initially, dopamine neurons fired in response to the unexpected juice reward. - As the monkey learned the association, the neurons stopped firing for the (now expected) reward and instead fired for the light that predicted it. - If the predicted reward was withheld, the dopamine neurons showed a dip in firing, signaling a negative prediction error.
This was a landmark discovery. The abstract, mathematically-derived TD prediction error from AI research had a direct, measurable correlate in the brain’s dopamine signal. This solidified the idea that the basal ganglia, a set of deep brain structures modulated by dopamine, are the brain’s core RL system.
Step 3: AI and Neuroscience Co-evolve
This discovery triggered an explosion of research in both fields. - In AI: The biological plausibility of RL fueled its development, leading to breakthroughs like DeepMind’s AlphaGo, which combined deep learning with RL to master the game of Go. - In Neuroscience: RL provided a powerful mathematical framework for understanding a vast range of brain functions and psychiatric disorders. Addiction, for example, can be modeled as a hijacking of the brain’s RL system, where drugs create an unnaturally strong positive prediction error that drives compulsive behavior.
The Mathematical Convergence: The temporal difference learning algorithm computes:
\[ \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) \]
where δ is the prediction error, r is the reward, γ is a discount factor, and V(s) is the estimated value of state s. Remarkably, dopamine neuron firing rates follow this exact equation, with: - Positive δ (reward better than expected) → increased firing - Negative δ (reward worse than expected) → decreased firing - δ ≈ 0 (reward as expected) → baseline firing
This quantitative match between a pure algorithmic derivation and biological neural activity is one of the most striking examples of computational neuroscience’s success.
Modern Extensions: The dopamine-RL connection has inspired further AI developments: - Actor-Critic Architectures: Separate networks for value estimation (critic, like ventral striatum) and policy (actor, like dorsal striatum) - Multi-timescale Learning: Different brain regions learn at different speeds; this has inspired hierarchical RL with multiple time horizons - Intrinsic Motivation: The brain doesn’t only learn from external rewards; curiosity and novelty-seeking are intrinsically rewarding. This inspired curiosity-driven RL where agents explore by seeking surprising states.
While AI has made incredible progress, it still lags behind the brain in several key areas. The brain’s solutions to these challenges offer a roadmap for the next generation of AI.
The human brain performs computations rivaling a supercomputer while running on just 20 watts of power (less than a standard lightbulb). In contrast, training a large AI model can consume as much energy as a small town. The brain achieves this remarkable efficiency through two main principles that AI is only beginning to explore: - Sparsity: At any given moment, only a small fraction of neurons in the brain are active. This is known as sparse coding, and it dramatically reduces energy consumption. Most ANNs, by contrast, involve dense, all-to-all computations where most “neurons” are active. - Event-Driven Processing: Biological neurons are event-driven; they only fire a “spike” and consume energy when they have something important to signal. Most ANNs operate on a fixed clock, processing entire tensors of data in every cycle, whether the information has changed or not.
The Path Forward: Spiking Neural Networks (SNNs) and neuromorphic hardware (Chapter 18) are direct attempts to incorporate these principles into AI, promising orders-of-magnitude improvements in energy efficiency.
A child can learn to recognize a cat from just a few examples, whereas a deep learning model needs to see millions of pictures. Furthermore, the brain learns continuously throughout life without forgetting previously learned skills. AI models, on the other hand, suffer from catastrophic forgetting: when trained on a new task, they often completely overwrite the knowledge of a previous one.
The brain’s solutions include: - Innate Structures: The brain is not a blank slate. It has a highly structured architecture shaped by evolution (e.g., the basic circuits of the visual cortex) that gives it a head start on learning. This is a powerful argument against “pure” learning and in favor of building useful inductive biases into our AI models. - Complementary Learning Systems: The brain has multiple memory systems. The hippocampus learns new episodes quickly, while the neocortex slowly integrates this new knowledge into its existing world model over time, often during sleep. This prevents new information from catastrophically interfering with old knowledge.
The Path Forward: Research in continual learning and meta-learning aims to replicate these abilities, exploring techniques like experience replay, synaptic consolidation, and modular architectures that can be dynamically expanded.
Few-Shot Learning from Neuroscience: The brain’s ability to learn from limited examples has inspired meta-learning approaches like Model-Agnostic Meta-Learning (MAML) and Prototypical Networks. These methods learn “how to learn” by training on a distribution of tasks, enabling rapid adaptation to new tasks with minimal data, much like how a child quickly learns new concepts by leveraging prior knowledge.
Synaptic Consolidation in AI: Elastic Weight Consolidation (EWC) directly mimics biological synaptic consolidation. After learning a task, the algorithm computes the importance of each network weight for that task (using the Fisher information matrix). When learning new tasks, important weights are protected from large changes, preventing catastrophic forgetting. This is analogous to how the brain selectively strengthens important synapses while allowing flexibility in others.
The brain is not a single, monolithic processor. It is a collection of highly specialized modules (for vision, hearing, language, motor control) that are tightly integrated. This modular design allows for both specialization and flexibility.
The Path Forward: While the trend in AI has been towards large, end-to-end models, the future may lie in building more modular, brain-like systems. This could involve creating hybrid architectures that combine specialized modules for perception, memory, and reasoning, coordinated by a central executive control network, much like the prefrontal cortex orchestrates activity across the rest of the brain.
Mixture of Experts: Modern AI is rediscovering modularity through architectures like Mixture of Experts (MoE), where different sub-networks specialize in different aspects of a problem, with a gating network deciding which experts to consult, reminiscent of how different brain regions are recruited for different cognitive tasks.
The attention mechanism that revolutionized deep learning has deep roots in neuroscience. The brain cannot process all incoming sensory information with equal depth; it would be computationally prohibitive. Instead, attention allows the brain to selectively allocate processing resources to the most relevant information.
Neuroscience Foundation: The parietal cortex, particularly areas like the lateral intraparietal area (LIP), plays a crucial role in spatial attention. Neurons in LIP create “priority maps” that highlight important locations in the visual field based on both bottom-up salience (bright, moving objects) and top-down goals (looking for a friend in a crowd). This selective amplification of relevant information is the biological basis of attention.
AI Implementation: The attention mechanism in Transformers (Vaswani et al., 2017) implements a similar principle computationally:
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
where queries (Q), keys (K), and values (V) allow the model to dynamically weight which input features are most relevant for the current computation. This “soft” lookup mechanism mirrors how the brain flexibly routes information based on context.
Closing the Loop: Recent neuroscience work has used AI attention models to better understand biological attention. By comparing attention weights in Transformers to neural activity patterns during attention tasks, researchers have found striking similarities in how both systems allocate resources, suggesting convergent solutions to the fundamental problem of selective information processing.
Impact: Attention mechanisms enabled the Transformer architecture, which has become the foundation of modern NLP (BERT, GPT) and is now transforming computer vision (Vision Transformers). This demonstrates how a core neuroscientific principle, selective information processing, can become a general-purpose computational tool.
The Biological Phenomenon: During sleep and quiet rest, the hippocampus replays recent experiences at accelerated speeds. Place cells that fired when a rat explored a maze will “replay” that same sequence during subsequent sleep, often hundreds of times faster than real-time. This replay is thought to be crucial for memory consolidation, transferring experiences from the hippocampus to the cortex for long-term storage.
AI Translation: This insight inspired experience replay in deep reinforcement learning. Rather than learning only from the most recent experience, RL agents store past experiences in a replay buffer and sample from it during training. This has two critical benefits:
Breaking Temporal Correlations: Consecutive experiences in an environment are highly correlated, which can destabilize learning. Random sampling from replay decorrelates the data.
Data Efficiency: Important or rare experiences can be replayed multiple times, similar to how the brain preferentially replays rewarding or surprising events.
Prioritized Experience Replay: DeepMind extended this with Prioritized Experience Replay (PER), which repl
ays experiences with high TD-error (surprising outcomes) more frequently. This directly mirrors findings that the hippocampus preferentially replays novel or rewarding experiences. The brain focuses its offline learning on what matters most.
Quantitative Impact: In Atari game learning, PER reduced the number of training frames needed to reach expert performance by 2-3×, demonstrating that biologically-inspired learning strategies can dramatically improve AI sample efficiency.
Beyond architectural inspiration, neuroscience has contributed specific algorithms that solve fundamental computational problems:
While backpropagation is the workhorse of deep learning, it’s biologically implausible (neurons don’t send error signals backwards). This has motivated research into more biologically plausible learning rules:
While backpropagation remains dominant for its efficiency, these alternatives suggest that the brain may achieve similar results through different, more distributed mechanisms.
The brain represents information sparsely: at any moment, only ~5% of neurons in a brain region are active. This sparsity has multiple benefits: - Energy Efficiency: Fewer active neurons means less energy consumption - Interference Reduction: Sparse representations minimize overlap, reducing interference between memories - Compression: Sparse codes are naturally compressed, storing information efficiently
AI Applications: Sparse autoencoders, k-sparse constraints in neural networks, and algorithms like k-SVD for dictionary learning all leverage sparsity for better generalization and interpretability. Sparse distributed representations (SDRs) are central to Numenta’s Hierarchical Temporal Memory, a brain-inspired AI framework.
Beyond Hebbian learning (“neurons that fire together wire together”), the brain uses homeostatic plasticity to maintain stable activity levels. If a neuron becomes too active, it downregulates its excitability; if too quiet, it upregulates.
AI Translation: Batch normalization, layer normalization, and techniques like adaptive learning rates serve similar stabilizing functions in deep learning, preventing runaway activation or gradient vanishing by maintaining balanced activity distributions across layers.
The convergence of neuroscience and AI is accelerating. The next decade promises even deeper integration:
AI for Neuroscience: As our ability to record neural data grows (with technologies like Neuropixels probes recording from thousands of neurons simultaneously, and fMRI achieving ever-higher spatial resolution) AI will become indispensable for making sense of it. Deep learning models already serve as the best predictive models of sensory cortex. Future applications include: - Neural Decoding: AI models that can decode the content of thoughts, mental imagery, or intended movements from brain activity in real-time - Large-Scale Simulations: Digital twins of brain circuits that can test hypotheses in silico before expensive in vivo experiments - Closed-Loop Experiments: AI systems that adaptively design the next experiment based on results from previous ones, accelerating the pace of discovery
Neuroscience for AI: As the limitations of current AI paradigms become clearer (brittleness to adversarial attacks, sample inefficiency, lack of causal reasoning, inability to generalize out-of-distribution) the brain will remain the ultimate source of inspiration. Specific near-term opportunities include: - Compositional Generalization: The brain’s ability to combine known concepts in novel ways (having never seen a “purple elephant,” you can immediately imagine one) remains elusive for AI - Active Learning: The brain strategically seeks information to reduce uncertainty; AI systems that actively explore and experiment could learn far more efficiently - Causal Models: The brain builds causal models of the world, enabling counterfactual reasoning and mental simulation; integrating causal inference (Chapter 9) into deep learning is a frontier challenge
Brain-Computer Interfaces (BCIs): The ultimate fusion of the two fields, where AI will be used to create bidirectional communication between the human brain and external devices (Chapter 20), will drive both fields forward at an unprecedented rate. BCIs require solving neuroscience problems (decoding neural signals) and AI problems (adapting to non-stationary neural data) simultaneously.
Hybrid Intelligence: Rather than replacing human intelligence, the future may involve tightly coupled human-AI systems where each contributes its strengths: human creativity, causal reasoning, and ethical judgment combined with AI’s pattern recognition, memory, and computational speed.
The journey of NeuroAI is one of closing the loop, weaving the study of natural and artificial intelligence into a single, unified scientific endeavor. The next great breakthroughs will likely come not from neuroscience alone, nor AI alone, but from their synergistic interaction, the virtuous cycle accelerating toward a deeper understanding of intelligence in all its forms.
This chapter focuses on the synthesis of concepts.TrueDespite remarkable progress, significant gaps remain between biological and artificial intelligence. These gaps represent opportunities for future breakthroughs:
The Problem: Deep neural networks are vulnerable to adversarial examples, imperceptibly altered inputs that cause confident misclassifications. A stop sign with carefully crafted stickers can be classified as a speed limit sign. Human vision is remarkably robust to such perturbations.
Neuroscience Insight: The brain’s robustness may stem from: - Recurrent Processing: Feedforward passes are refined by feedback, allowing error correction - Multi-scale Integration: The brain simultaneously processes information at multiple spatial and temporal scales - Predictive Processing: Top-down predictions interact with bottom-up signals, filtering out inconsistencies
Research Direction: Incorporating these principles, particularly recurrent dynamics and predictive coding, may yield more robust AI systems.
The Problem: AI systems struggle to generalize compositionally. Given training on “red triangle” and “blue circle,” humans easily understand “blue triangle,” but neural networks often fail. Language provides stark examples: we understand novel sentences by composing known words and grammatical rules.
Neuroscience Insight: The brain appears to use compositional representations: - Grid Cells: Represent space through a compositional code combining multiple spatial scales - Language Networks: The left frontal cortex implements compositional syntax rules - Concept Cells: Individual neurons can respond to abstract concepts (“the concept of Jennifer Aniston”) rather than just specific features
Research Direction: Developing neural architectures with explicit compositional structure (like Neural Module Networks or Capsule Networks) that mirror the brain’s compositional representations.
###17.7.3 Continual and Transfer Learning
The Problem: AI systems trained on Task A typically cannot be directly applied to Task B without extensive retraining and often suffer catastrophic forgetting. Humans excel at transfer learning, applying knowledge from one domain to another.
Neuroscience Insight: The brain achieves continual learning through: - Complementary Learning Systems: Fast hippocampal encoding + slow cortical consolidation - Abstract Representations: The prefrontal cortex maintains task-general representations that transfer across contexts - Meta-Learning: The brain learns learning algorithms themselves, enabling rapid adaptation to new tasks
Research Direction: Progressive neural networks, meta-learning (learning to learn), and modular architectures that can expand dynamically are promising approaches inspired by these principles.
The Problem: Current AI excels at pattern recognition but struggles with causal reasoning. AI systems can predict that objects fall when dropped (statistical regularity) but don’t understand why (gravity causes the fall). This limits their ability to reason about novel situations and plan interventions.
Neuroscience Insight: The brain builds causal models: - Mental Simulation: The hippocampus and prefrontal cortex can simulate future scenarios offline - Counterfactual Reasoning: Humans naturally reason about “what would have happened if…” - Causal Learning: The brain infers causal structure from observation and intervention (as in childhood learning through play and exploration)
Research Direction: Integrating causal inference frameworks (Chapter 9) with deep learning, developing AI systems that build and reason over causal graphs, and enabling agents to perform mental simulations.
The Virtuous Cycle: Explain the bidirectional relationship between neuroscience and AI that characterizes the NeuroAI virtuous cycle. Provide one concrete example of each direction (brain inspiring AI, and AI enabling neuroscience).
Hierarchical Processing: Both the visual cortex and Convolutional Neural Networks employ hierarchical processing. Describe what this means and explain why this architectural principle is beneficial for vision tasks in both biological and artificial systems.
Prediction Errors: The discovery that dopamine neurons encode temporal difference (TD) prediction errors was a landmark finding linking RL and neuroscience. Explain what a prediction error is and why it’s useful for learning. What happens to the dopamine signal as learning progresses?
Energy Efficiency: The human brain operates on approximately 20 watts of power. Describe the two main principles (sparsity and event-driven processing) that enable this remarkable efficiency, and contrast them with how conventional artificial neural networks operate.
Sparse Coding Analysis: Consider a neural network layer with 1000 neurons. In a dense representation, all neurons are active (mean activation > 0.1) for any input. In a sparse representation, only 5% of neurons are active per input.
CNN Feature Hierarchy: Implement a simple 3-layer convolutional network and visualize what features are learned at each layer when trained on a simple dataset (e.g., handwritten digits). Compare the complexity of features across layers and relate this to the V1-V4-IT hierarchy in the brain.
TD Learning Simulation: Implement a simple temporal difference learning algorithm for a reward prediction task. Simulate the classic Schultz experiment: train an agent to associate a stimulus with a reward, then show how the prediction error (dopamine signal) shifts from the reward to the predictive cue over trials.
Catastrophic Forgetting: Train a small neural network on Task A (e.g., classifying digits 0-4), then train it on Task B (classifying digits 5-9). Measure and report the drop in performance on Task A. Then implement a simple experience replay buffer and show how it mitigates catastrophic forgetting.
Limitations of the Analogy: While the parallels between CNNs and the visual cortex are striking, there are also important differences. Discuss at least three ways in which modern CNNs differ from biological vision systems. What might these differences reveal about the limitations of current AI approaches?
Ethical Implications of Brain-Like AI: As we succeed in creating more brain-like artificial intelligence, what new ethical considerations might arise? Consider the questions of consciousness, moral status, and the “rights” of increasingly sophisticated AI systems.
Future Directions: The chapter identifies three key lessons from the brain for future AI: energy efficiency, learning efficiency, and modular integration. Which of these do you think is the most critical bottleneck for current AI systems, and why? What would be the potential impact of solving this challenge?
This chapter illuminated the powerful, bidirectional relationship between neuroscience and AI, framing it as a virtuous cycle of discovery.
Looking Back - This chapter is a synthesis of the entire handbook, directly connecting the biological principles from Parts I & II with the AI architectures from Parts III & IV. The case studies on vision and RL directly reference concepts from Chapters 4, 5, and 8.
Looking Forward - Chapter 15 (Ethical AI): The prospect of creating more brain-like AI, as discussed here, raises profound ethical questions about consciousness, agency, and responsibility. - Chapter 16 (Future Directions): The future directions outlined here—such as continual learning and energy-efficient computing—are explored in greater detail in the final part of the book. - Chapter 18 (Neuromorphic Computing): This chapter will dive deep into the hardware designed to implement the brain’s principles of efficiency.
Fukushima, K. (1980). Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36(4), 193-202.
Hassabis, D., Kumaran, D., Summerfield, C., & Botvinick, M. (2017). Neuroscience-inspired artificial intelligence. Neuron, 95(2), 245-258.
Hubel, D. H., & Wiesel, T. N. (1962). Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. Journal of Physiology, 160(1), 106-154.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 25, 1097-1105.
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
Marblestone, A. H., Wayne, G., & Kording, K. P. (2016). Toward an integration of deep learning and neuroscience. Frontiers in Computational Neuroscience, 10, 94.
Schultz, W., Dayan, P., & Montague, P. R. (1997). A neural substrate of prediction and reward. Science, 275(5306), 1593-1599.
Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction (2nd ed.). MIT Press.
Yamins, D. L., & DiCarlo, J. J. (2016). Using goal-driven deep learning models to understand sensory cortex. Nature Neuroscience, 19(3), 356-365.
Yamins, D. L., Hong, H., Cadieu, C. F., Solomon, E. A., Seibert, D., & DiCarlo, J. J. (2014). Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proceedings of the National Academy of Sciences, 111(23), 8619-8624.